| Version 66 (modified by , 4 years ago) ( diff ) |
|---|
Submitting Jobs on Cypress
In this section we will examine how to submit jobs on Cypress using the SLURM resource manager. We’ll begin with the basics and proceed to examples of jobs which employ MPI, OpenMP, and hybrid parallelization schemes.
Quick Start for PBS users
Cypress uses SLURM to schedule jobs and manage resources resources. Full documentation and tutorials for SLURM can be found on the SLURM website at:
http://slurm.schedmd.com/documentation.html
Additionally, those who are familiar with the Torque-PBS manager used on Aries and Sphynx may find the "SLURM Rosetta Stone" particularly useful:
http://slurm.schedmd.com/rosetta.html
Lastly, resource limits on Cypress divided into separate Quality Of Services (QOSs). These are analogous to the queues on Sphynx. You may choose a QOS by using the appropriate script directive in your submission script, e.g.
#SBATCH --qos=long
The default QOS is normal. For a list of which QOS are available and the associated limits please see the about section of this wiki.
Using SLURM on Cypress
Introduction to Managed Cluster Computing
For those who are new to cluster computing and resource management, let's begin with an explanation of what a resource manager is and why it is necessary. Suppose you have a piece of C code that you would like to compile and execute, for example a helloworld program.
#include<stdio.h> int main(){ printf("Hello World\n"); return 0; }
On your desktop you would open a terminal, compile the code using your favorite c compiler and execute the code. You can do this without worry as you are the only person using your computer and you know what demands are being made on your CPU and memory at the time you run your code. On a cluster, many users must share the available resources equitably and simultaneously. It's the job of the resource manager to choreograph this sharing of resources by accepting a description of your program and the resources it requires, searching the available hardware for resources that meet your requirements, and making sure that no one else is given those resources while you are using them.
Occasionally the manager will be unable to find the resources you need due to usage by other user. In those instances your job will be "queued", that is the manager will wait until the needed resources become available before running your job. This will also occur if the total resources you request for all your jobs exceed the limits set by the cluster administrator. This ensures that all users have equal access to the cluster.
The take home point here is this: in a cluster environment a user submits jobs to a resource manager, which in turn runs an executable(s) for the user. So how do you submit a job request to the resource manager? Job requests take the form of scripts, called job scripts. These scripts contain script directives, which tell the resource manager what resources the executable requires. The user then submits the job script to the scheduler.
The syntax of these script directives is manager specific. For the SLURM resource manager, all script directives begin with "#SBATCH". Let's look at a basic SLURM script requesting one node and one core on which to run our helloworld program.
#!/bin/bash #SBATCH --job-name=HiWorld ### Job Name #SBATCH --output=Hi.out ### File in which to store job output #SBATCH --error=Hi.err ### File in which to store job error messages #SBATCH --qos=normal ### Quality of Service (like a queue in PBS) #SBATCH --time=0-00:01:00 ### Wall clock time limit in Days-HH:MM:SS #SBATCH --nodes=1 ### Node count required for the job #SBATCH --ntasks-per-node=1 ### Nuber of tasks to be launched per Node ./helloworld
Notice that the SLURM script begins with #!/bin/bash. This tells the Linux shell what flavor shell interpreter to run. In this example we use BASh (Bourne Again Shell). The choice of interpreter (and subsequent syntax) is up to the user, but every SLURM script should begin this way. This is followed by a collection of #SBATCH script directives telling the manager about the resources needed by our code and where to put the codes output. Lastly, we have the executable we wish the manager to run (note: this script assumes it is located in the same directory as the executable).
For Workshop : If you use a temporary workshop account, modify the script like:
#!/bin/bash #SBATCH --job-name=HiWorld ### Job Name #SBATCH --output=Hi.out ### File in which to store job output #SBATCH --error=Hi.err ### File in which to store job error messages #SBATCH --partition=workshop # Partition #SBATCH --qos=workshop # Quality of Service ##SBATCH --qos=normal ### Quality of Service (like a queue in PBS) #SBATCH --time=0-00:01:00 ### Wall clock time limit in Days-HH:MM:SS #SBATCH --nodes=1 ### Node count required for the job #SBATCH --ntasks-per-node=1 ### Nuber of tasks to be launched per Node ./helloworld
With our SLURM script complete, we’re ready to run our program on the cluster. To submit our script to SLURM, we invoke the sbatch command. Suppose we saved our script in the file helloworld.srun (the extension is not important). Then our submission would look like:
[tulaneID@cypress1 ~]$ sbatch helloworld.srun Submitted batch job 6041 [tulaneID@cypress1 ~]$
Our job was successfully submitted and was assigned the job number 6041. We can check the output of our job by examining the contents of our output and error files. Referring back to the helloworld.srun SLURM script, notice the lines
#SBATCH --output=Hi.out ### File in which to store job output #SBATCH --error=Hi.err ### File in which to store job error messages
These specify files in which to store the output written to standard out and standard error, respectively. If our code ran without issue, then the Hi.err file should be empty and the Hi.out file should contain our greeting.
[tulaneID@cypress1 ~]$ cat Hi.err [tulaneID@cypress1 ~]$ cat Hi.out Hello World [tulaneID@cypress1 ~]$
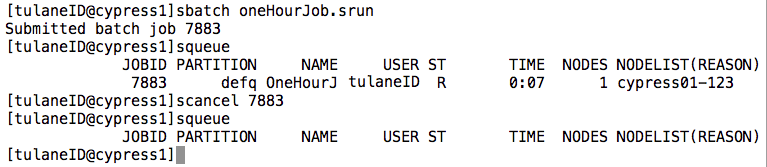
There are two more commands we should familiarize ourselves with before we begin. The first is the “squeue” command. This shows us the list of jobs that have been submitted to SLURM that are either currently running or are in the queue waiting to run. The last is the “scancel” command. This allows us to terminate a job that is currently in the queue. To see these commands in action, let's simulate a one hour job by using the sleep command at the end of a new submission script.
#!/bin/bash #SBATCH --job-name=OneHourJob ### Job Name #SBATCH --time=0-00:01:00 ### Wall clock time limit in Days-HH:MM:SS #SBATCH --nodes=1 ### Node count required for the job #SBATCH --ntasks-per-node=1 ### Nuber of tasks to be launched per Node sleep 3600
Notice here that we've omitted some of the script directives included in our previous hello world submission script. We will still run on the normal QOS as that's the default on Cypress. However, when no output directives are given SLURM will redirect the output of our executable (including any error messages) to a file labeled with our jobs ID number. This number is assigned upon submission. Let's suppose that the above is stored in a file named oneHourJob.srun and we submit our job using the sbatch command. Then we can check on the progress of our job using squeue and we can cancel the job by executing scancel on the assigned job ID.

Notice that when we run the squeue command, our job status is marked R for running and has been running for 7 seconds. The squeue command also tells us what node our job is being run on, in this case node 123. When running squeue in a research environment you will usually see a long list of users running multiple jobs. To single out your own job you can use the "-u" option flag to specify your user name.
Congratulations, you are ready to begin running jobs on Cypress!
Requesting Wall-time duration
Cypress has several Quality of Services (QOSs) available for jobs. Each QOS has limits on the requestable resources, as shown below:
| QOS limits | |||
|---|---|---|---|
| QOS name | maximum job size (node-hours) | maximum walltime per job | maximum nodes per user |
| interactive | N/A | 1 hour | 1 |
| normal | N/A | 24 hours | 18 |
| long | 168 | 168 hours | 8 |
The "normal" QOS is intended for users running parallel programs. This is the preferred type of usage to best take advantage of Cypess's parallel processing capability. Each user is limited to simultaneous usage of 18 nodes (360 cores) over all his/her jobs. The maximum time you can request with "normal" QOS is 24 hours.
#SBATCH --qos=normal #SBATCH --time=24:00:00
The "long" QOS is intended for jobs which are not very parallel, but have longer runtime. Each job has a job-size limit of 168 node-hours, calculated as the number of nodes requested multiplied by number of hours requested. For example a job submitted to the long QOS may request 1 node for 7 days, or 2 nodes for 3.5 days. You are limited to 8 nodes across all your jobs in this QOS. So, for example, you may run up to 8 jobs each using 1 node and running for 7 days. The maximum time you can request with "long" QOS is 7 days with a single node.
#SBATCH --qos=long #SBATCH --time=7-00:00:00 #SBATCH --nodes=1
The "interactive" QOS is intended to be used for testing SLURM script submission, and is limited to 1 job per user. See interactiveQOS
Requesting memory for your job
Our standard nodes on Cypress will allow you to use up to 64 GB of memory per node (3.2 GB per core requested). This should be sufficient for many types of jobs, and you do not need to do anything if your job uses less than this amount of memory. If your jobs require more memory to run, use the --mem option of sbatch to request a larger amount of memory. For example, to request 16 GB of memory per node, put the following in your sbatch script:
#SBATCH --mem=16000
If you need more than 64 GB of memory per node, we have a few larger memory nodes available. To request 128 GB nodes for your job, put the following in your sbatch script:
#SBATCH --mem=128000
or, to request 256 GB memory nodes, use the following:
#SBATCH --mem=256000
We have a limited number of the larger memory nodes, so please only request a larger amount of memory if your job requires it. You can ask SLURM for an estimate of the amount of memory used by jobs you have previously run using sacct -j <jobid> -o maxvmsize . For example:
$ sacct -j 2660 -o maxvmsize
MaxVMSize
----------
39172520K
This shows that job 2660 allocated close to 40 GB of memory.
Job scheduling and priority
We would like each of our research groups to have equal opportunity to use the cluster. Instead of giving each research group a fixed allocation of CPU-time (where the ability to run jobs is cut off after the allocation is reached), SLURM uses a "Fair-share" feature to attempt to give each research group its fair share of resources. Each job has a priority, which is a number that determines which queued jobs are to be scheduled to run first.
You may use the "sprio" command to see the priority of queued jobs. For example, the command:
sprio -o "%Y %u %i" | sort -nr
will return a list of queued jobs in priority order, and
sprio -j <jobid>
(where <jobid> should be replaced by the actual Job ID) will show the components which go into the priority. These components are:
- Fair-share: Fair-share is based on historical usage. For details on SLURM's Fair-share implementation, see here: https://slurm.schedmd.com/priority_multifactor.html#fairshare . In short, the more CPU-time previously used, the lower the priority for subsequent jobs will (temporarily) become. SLURM has a half-life decay parameter so that more recent usage is weighted more strongly. We set this half-life on Cypress to 1 week.
- Age: Jobs that have been waiting in the queue longer get higher priority.
- Job Size: Larger jobs (i.e. jobs with more CPUs/nodes requested) have higher priority to favor jobs that take advantage of parallel processesing (e.g. MPI jobs).
SLURM calculates each priority component as a fraction (value between 0 and 1), which is then multiplied by a weight. The current weights are: Fair-share: 100,000; Age: 10,000; Job Size: 1,000. That is, Fair-share is the major contributor to priority. The weighted components are added to give the final priority.
MPI Jobs
Now let’s look at how to run an MPI based job across multiple nodes. SLURM does a nice job of interfacing with the mpirun command to minimize the amount of information the user needs to provide. For instance, SLURM will automatically provide a hostlist and the number of processes based on the script directives provided by the user.
Let’s say that we would like to run an MPI based executable named myMPIexecutable. Let’s further suppose that we wished to run it using a total of 80 MPI processes. Recall that each node of Cypress is equipped with two Intel Xeon 10 core processors. Then a natural way of breaking up our problem would be to run it on four nodes using 20 processes per core. Here we run into the semantics of SLURM. We would ask SLURM for four nodes and 20 “tasks” per node.
#!/bin/bash #SBATCH --qos=normal #SBATCH --job-name=MPI_JOB #SBATCH --time=0-01:00:00 #SBATCH --output=MPIoutput.out #SBATCH --error=MPIerror.err #SBATCH --nodes=4 #SBATCH --ntasks-per-node=20 module load intel-psxe/2015-update1 ############ THE JOB ITSELF ############################# echo Start Job echo nodes: $SLURM_JOB_NODELIST echo job id: $SLURM_JOB_ID echo Number of tasks: $SLURM_NTASKS mpirun myMPIexecutable echo End Job
Again, notice that we did not need to feed any of the usual information to mpirun regarding the number of processes, hostfiles, etc. as this is handled automatically by SLURM. Another thing to note is the loading the intel-psxe (parallel studio) module. This loads the Intel instantiation of MPI including mpirun. If you would like to use OpenMPI then you should load the openmpi/gcc/64/1.8.2-mlnx-ofed2 module or one of the other OpenMPI versions currently available on Cypress. We also take advantage of a couple of SLURMS output environment variables to automate our record keeping. Now, a record of what nodes we ran on, our job ID, and the number of tasks used will be written to the MPIoutput.out file. While this is certainly not necessary, it often pays dividends when errors arise.
OpenMP Jobs
When running OpenMP (OMP) jobs on Cypress, it’s necessary to set your environment variables to reflect the resources you’ve requested. Specifically, you must export the variable OMP_NUM_THREADS so that its value matches the number of cores you have requested from SLURM. This can be accomplished through the use of SLURMS built in export environment variables.
#!/bin/bash #SBATCH --qos=normal #SBATCH --job-name=OMP_JOB #SBATCH --time=1-00:00:00 #SBATCH --nodes=1 #SBATCH --ntasks-per-node=1 #SBATCH --cpus-per-task=20 export OMP_NUM_THREADS=$SLURM_CPUS_PER_TASK ./myOMPexecutable
In the script above we request 20 cores on one node of Cypress (which is all the cores available on any node). As SLURM regards tasks as being analogous to MPI processes, it’s better to use the cpus-per-task directive when employing OpenMP parallelism. Additionally, the SLURM export variable $SLURM_CPUS_PER_TASK stores whatever value we assign to cpus-per-task, and is therefore our candidate for passing to OMP_NUM_THREADS.
Hybrid Jobs
When running MPI/OpenMP hybrid jobs on Cypress, for example,
#!/bin/bash #SBATCH --qos=normal # Quality of Service #SBATCH --job-name=hybridTest # Job Name #SBATCH --time=00:10:00 # WallTime #SBATCH --nodes=2 # Number of Nodes #SBATCH --ntasks-per-node=2 # Number of tasks (MPI processes) #SBATCH --cpus-per-task=10 # Number of threads per task (OMP threads) export OMP_NUM_THREADS=$SLURM_CPUS_PER_TASK mpirun ./myHybridExecutable
In the script above we request 2 tasks per node and 10 cpus per task, which means 20 cores per node and all the cores available on one node. We request 2 nodes so that we can use 4 MPI processes. Each process can use 10 OpenMP threads.
MIC Native Jobs
There are two Intel Xeon Phi co-processors (MIC) on each node of Cypress. To run your code natively on MIC, make sure you have to compile the code with "-mmic" option. The executable for MIC code cannot run on host CPU. To launch the MIC native executable from host, use "micnativeloadex" command. One possible SLURM jobs script is, for example,
#!/bin/bash #SBATCH --qos=normal # Quality of Service #SBATCH --job-name=nativeTest # Job Name #SBATCH --time=00:10:00 # WallTime #SBATCH --nodes=1 # Number of Nodes #SBATCH --ntasks-per-node=1 # Number of tasks (MPI presseces) #SBATCH --cpus-per-task=1 # Number of processors per task OpenMP threads() #SBATCH --gres=mic:1 # Number of Co-Processors micnativeloadex ./myNativeExecutable -e "OMP_NUM_THREADS=100" -d 0 -v
In the script above we request one MIC device that will be device number 0. "micnativeloadex" command launches MIC native executable. "-e "OMP_NUM_THREADS=100"" option to set the number of threads on the MIC device to 100. For more options, see below.
[fuji@cypress01-090 nativeTest]$ micnativeloadex -h Usage: micnativeloadex [ -h | -V ] AppName -l -t timeout -p -v -d coprocessor -a "args" -e "environment" -a "args" An optional string of command line arguments to pass to the remote app. -d The (zero based) index of the Intel(R) Xeon Phi(TM) coprocessor to run the app on. -e "environment" An optional environment string to pass to the remote app. Multiple environment variable may be specified using spaces as separators: -e "LD_LIBRARY_PATH=/lib64/ DEBUG=1" -h Print this help message -l Do not execute the binary on the coprocessor. Instead, list the shared library dependency information. -p Disable console proxy. -t Time to wait for the remote app to finish (in seconds). After the timeout is reached the remote app will be terminated. -v Enable verbose mode. Note that verbose output will be displayed if the remote app terminates abnormally. -V Show version and build information
Notify Job-state-change by email
You can set to receive email when job becomes active and/or job finishes.
For example, by adding following two lines into SLURM script, you will receive emails when the job begins and ends.
#SBATCH --mail-type=ALL #SBATCH [email protected]
Valid values for '--mail-type=' are: BEGIN, END, FAIL, REQUEUE and ALL. With ALL, you will get emails at any state change.
Running Manny Serial/Parallel Jobs
Jobs Array
If you are running a large number of serial jobs, it is recommended to submit them as a job array to make the best use of your allocated resources. For example, suppose you are running 100 serial jobs using scripts located in a "scripts" folder, each of which does a serial calculation: scripts/run1.sh, scripts/run2.sh, ..., scripts/run100.sh. You would create an sbatch script named "run100scripts.srun" with contents:
#!/bin/bash #SBATCH -J array_example #SBATCH --array=0-4 #SBATCH -N 1 #SBATCH -n 20 #SBATCH --time=01:00:00 srun ./runscript.sh
The contents of the script "runscript.sh" would be:
#!/bin/bash RUNNUMBER=$((SLURM_ARRAY_TASK_ID*SLURM_NTASKS + SLURM_PROCID + 1)) ./scripts/run$RUNNUMBER.sh
Make sure your scripts have executable permissions. Then, submitting with:
sbatch run100scripts.srun
will run the 100 scripts as a 5 job array, with 20 tasks each.
See here for more about job-array.
Jobs Dependency
Job dependencies are used to defer the start of a job until the specified dependencies have been satisfied. They are specified with the --dependency option to sbatch command.
sbatch --dependency=<type:job_id[:job_id][,type:job_id[:job_id]]> ...
Dependency types:
- after:jobid[:jobid...] job can begin after the specified jobs have started
- afterany:jobid[:jobid...] job can begin after the specified jobs have terminated
- afternotok:jobid[:jobid...] job can begin after the specified jobs have failed
- afterok:jobid[:jobid...] job can begin after the specified jobs have run to completion with an exit code of zero (see the user guide for caveats).
See here for more about job-dependency.
Submitting Interactive Jobs
For those who develop their own codes, we provide the app, idev to make interactive access to a set of compute nodes, in order to quickly compile, run and validate MPI or other applications multiple times in rapid succession.
The app idev, (Interactive DEVelopment)
The idev application creates an interactive development environment from the user's login window. In the idev window the user is connected directly to a compute node from which the user can launch executables directly.
The idev command submits a batch job that creates a copy of the batch environment and then goes to sleep. After the job begins, idev acquires a copy of the batch environment, SSH's to the master node, and then re-creates the batch environment.
How to use idev
On Cypress login nodes (cypress1 or cypress2),
[user@cypress1 ~]$ idev
In default, idev submit a job requesting one node for one hour. It also requests two Intel Phi (MIC) co-processors.
If there is an available node, your job will become active immediately and idev app initiates a ssh session to the computing node. For example:
[fuji@cypress1 ~]$ idev Requesting 1 node(s) task(s) to normal queue of defq partition 1 task(s)/node, 20 cpu(s)/task, 2 MIC device(s)/node Time: 0 (hr) 60 (min). Submitted batch job 8981 JOBID=8981 begin on cypress01-100 --> Creating interactive terminal session (login) on node cypress01-100. --> You have 0 (hr) 60 (min). Last login: Mon Apr 27 14:45:38 2015 from cypress1.cm.cluster [fuji@cypress01-100 ~]$
Note the prompt, "cypress01-100", in the above session. It is your interactive compute-node prompt. You can load modules, compile codes and test codes.
idev transfers the environmental variables to computing node. Therefore, if you have loaded some modules on the login node, you don't have to load the same module again.
How to exit idev
Once you're in the interactive session, at any time before the interactive session times out, you can terminate or leave the interactive session via the exit command, and you will be sent back to your login session on the login node with your most recent login prompt.
[fuji@cypress01-100 ~]$ exit [fuji@cypress1 ~]$
For Workshop
If you use a temporary workshop account, do this.
export MY_PARTITION=workshop export MY_QUEUE=workshop
Options
By default only a single node is requested for 60 minutes. However, you can change the limits with command line options, using syntax similar to the request specifications used in a job script.
The syntax is conveniently described in the idev help display:
[fuji@cypress1 ~]$ idev --help -c|--cpus-per-task= : Cpus per Task -N|--nodes= : Number of Nodes -n|--ntasks-per-node= : Number of Tasks per Node --mic= : Number of MIC per Node --mem= : Memory (MB) per Node -t|--time= : Wall Time --port= : prot forward [local port]:[remote port]
For example, if you want to use 4 nodes for 4 hours,
[fuji@cypress1 ~]$ idev -N 4 -t 4:00:00 Requesting 4 node(s) task(s) to normal queue of defq partition 1 task(s)/node, 20 cpu(s)/task, 2 MIC device(s)/node Time: 04 (hr) 00 (min). Submitted batch job 8983 JOBID=8983 begin on cypress01-100 --> Creating interactive terminal session (login) on node cypress01-100. --> You have 04 (hr) 00 (min). Last login: Mon Apr 27 14:48:45 2015 from cypress1.cm.cluster [fuji@cypress01-100 ~]$
MIC native run
You can login to MIC device and run native codes. There are two MIC devices on each node, mic0 and mic1.
[fuji@cypress01-100 nativeTest]$ ssh mic0 fuji@cypress01-100-mic0:~$
The prompt, "cypress01-100-mic0" in the above session is your interactive MIC device prompt. Note that you cannot run CPU code there. Therefore, you cannot compile code on device, even compiling for native code. The environmental variables are not set and also module command doesn't work. To run your native executable that uses shared libraries, you have to set environmental variables manually, like
export LD_LIBRARY_PATH=/share/apps/intel_parallel_studio_xe/2015_update1/lib/mic:$LD_LIBRARY_PATH
"interactive" QOS
The "interactive" QOS is intended to be used for testing SLURM script submission, and is limited to 1 job per user. To use it, set your partition and QOS to "interactive". For example, with idev:
export MY_PARTITION=interactive export MY_QUEUE=interactive idev
Be sure to unset these variables to resume normal job submission:
unset MY_PARTITION unset MY_QUEUE
Other QOS's on the system are for staff testing use only.
Temporarily Setting Environment Variables
As an alternative to the above, you can avoid possible confusion associated with environment variable values by temporarily setting those variables and invoking a command, e.g. idev, all on one line. Thus, when you exit from the interactive session, those variables will be restored to their prior state. Furthermore, you can define and use an alias, e.g. "idevi", as in the following.
Starting from the login session, observe variables initially unset.
[fuji@cypress1 ~]$ echo MY_PARTITION=$MY_PARTITION, MY_QUEUE=$MY_QUEUE MY_PARTITION=, MY_QUEUE=
Define and invoke alias "idevi", now entering the interactive session.
[fuji@cypress1 ~]$ alias idevi='MY_PARTITION=interactive MY_QUEUE=interactive idev' [fuji@cypress1 ~]$ idevi Requesting 1 node(s) task(s) to interactive queue of interactive partition 1 task(s)/node, 20 cpu(s)/task, 2 MIC device(s)/node Time: 0 (hr) 60 (min). Submitted batch job 1255374 JOBID=1255374 begin on cypress01-089 --> Creating interactive terminal session (login) on node cypress01-089. --> You have 0 (hr) 60 (min). --> Assigned Host List : /tmp/idev_nodes_file_fuji Last login: Thu Dec 19 12:27:32 2019 from cypress1.cm.cluster
In the interactive session, evaluate the variables and observe they are set.
[fuji@cypress01-089 ~]$ echo MY_PARTITION=$MY_PARTITION, MY_QUEUE=$MY_QUEUE MY_PARTITION=interactive, MY_QUEUE=interactive
In the interactive session, do work, then exit back to the login session.
... [fuji@cypress01-089 ~]$ exit logout Connection to cypress01-089 closed. Removing job 1255374. [fuji@cypress1 ~]$
Back in the login session, observe the variables are restored to their prior state - in this case unset.
[fuji@cypress1 ~]$ echo MY_PARTITION=$MY_PARTITION, MY_QUEUE=$MY_QUEUE MY_PARTITION=, MY_QUEUE=
Questions or Suggestions
If you have ideas for enhancing idev with new features or any questions, please send email to hpcadmin@….
Attachments (3)
-
Hi_output.png
(26.9 KB
) - added by 11 years ago.
contents_of_Hi_files
-
sbatch.png
(24.4 KB
) - added by 11 years ago.
sbatch_example
- squeue_scancel2.png (37.4 KB ) - added by 11 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip