| Version 13 (modified by , 11 years ago) ( diff ) |
|---|
Submitting Jobs on Cypress
In this section we will examine how to submit jobs on Cypress using the SLURM resource manager. We’ll begin with the basics and proceed to examples of jobs which employ MPI, OpenMP, and hybrid parallelization schemes.
Quick Start for PBS users
Cypress uses SLURM to manage job submission and reserve resources. Full documentation and tutorials for SLURM can be found on the SLURM website at:
http://slurm.schedmd.com/documentation.html
Additionally, those who are familiar with the Torque-PBS manager used on Aries and Sphynx may find the "SLURM Rosetta Stone" particularly useful:
http://slurm.schedmd.com/rosetta.html
Lastly, resource limits on Cypress divided into separate Quality Of Services (QOSs). These are analogous to the queues on Sphynx. You may choose a QOS by using the appropriate script directive in your submission script, e.g.
#SBATCH --qos=long
The default QOS is normal. For a list of which QOS are available and the associated limits please see the about section of this wiki.
Introduction to Managed Cluster Computing
For those who are new to cluster computing and resource management, let's begin with an explanation of what a resource manager is and why it is necessary. Suppose you have a piece of C code that you would like to compile and execute, for example a helloworld program.
#include<stdio.h> int main(){ printf("Hello World\n"); return 0; }
On your desktop you would open a terminal, compile the code using your favorite c compiler and execute the code. You can do this without worry as you are the only person using your computer and you know what demands are being made on your CPU and memory at the time you run your code. On a cluster, many users must share the available resources equitably and simultaneously. It's the job of the resource manager to choreograph this sharing of resources by accepting a description of your program and the resources it requires, searching the available hardware for resources that meet your requirements, and making sure that no one else is given those resources while you are using them.
Occasionally the manager will be unable to find the resources you need due to usage by other user. In those instances your job will be "queued", that is the manager will wait until the needed resources become available before running your job. This will also occur if the total resources you request for all your jobs exceed the limits set by the cluster administrator. This ensures that all users have equal access to the cluster.
The take home point here is this: in a cluster environment a user submits jobs to a resource manager, which in turn runs an executable(s) for the user. So how do you submit a job request to the resource manager? Job requests take the form of scripts, called job scripts. These scripts contain script directives, which tell the resource manager what resources the executable requires. The user then submits the job script to the scheduler.
The syntax of these script directives is manager specific. For the SLURM resource manager, all script directives begin with "#SBATCH". Let's look at a basic SLURM script requesting one node and one core on which to run our helloworld program.
#!/bin/bash #SBATCH --job-name=HiWorld ### Job Name #SBATCH --output=Hi.out ### File in which to store job output #SBATCH --error=Hi.err ### File in which to store job error messages #SBATCH --qos=normal ### Quality of Service (like a queue in PBS) #SBATCH --time=0-00:01:00 ### Wall clock time limit in Days-HH:MM:SS #SBATCH --nodes=1 ### Node count required for the job #SBATCH --ntasks-per-node=1 ### Nuber of tasks to be launched per Node ./helloworld
Notice that the SLURM script begins with #!/bin/bash. This tells the Linux shell what flavor shell interpreter to run. In this example we use BASh (Bourne Again Shell). The choice of interpreter (and subsequent syntax) is up to the user, but every SLURM script should begin this way. This is followed by a collection of #SBATCH script directives telling the manager about the resources needed by our code and where to put the codes output. Lastly, we have the executable we wish the manager to run (note: this script assumes it is located in the same directory as the executable).
With our SLURM script complete, we’re ready to run our program on the cluster. To submit our script to SLURM, we invoke the “sbatch” command. Suppose we saved our script in the file helloworld.srun (the extension is not important). Then our submission would look like:

Our job was successfully submitted and was assigned the job number 6041. We can check the output of our job by examining the contents of our output and error files. Referring back to the helloworld.srun SLURM script, notice the lines
#SBATCH --output=Hi.out ### File in which to store job output #SBATCH --error=Hi.err ### File in which to store job error messages
These specify files in which to store the output written to standard out and standard error, respectively. If our code ran without issue, then the Hi.err file should be empty and the Hi.out file should contain our greeting.

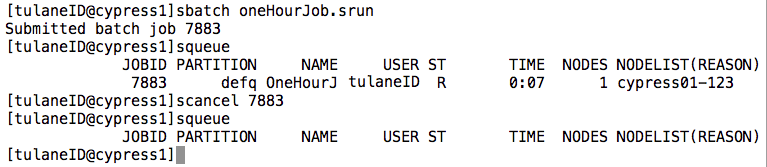
There are two more commands we should familiarize ourselves with before we begin. The first is the “squeue” command. This shows us the list of jobs that have been submitted to SLURM that are either currently running or are in the queue waiting to run. The last is the “scancel” command. This allows us to terminate a job that is currently in the queue. So that we can see these commands in action, let’s extend our jobs run time by adding a sleep command to the end of our SLURM script.

Congratulations, you are now ready to start running jobs on Cypress.
Attachments (3)
-
Hi_output.png
(26.9 KB
) - added by 11 years ago.
contents_of_Hi_files
-
sbatch.png
(24.4 KB
) - added by 11 years ago.
sbatch_example
- squeue_scancel2.png (37.4 KB ) - added by 11 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip