| Version 2 (modified by , 11 years ago) ( diff ) |
|---|
Parallel Computing
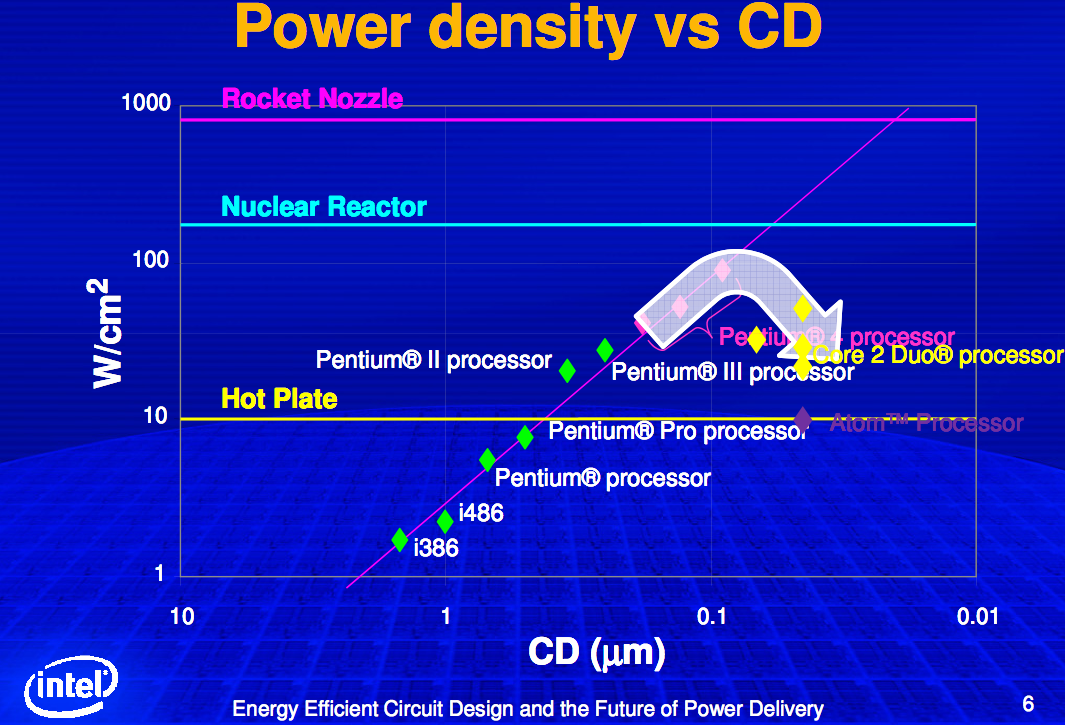
Moore's law
.png)
- 2X transistors/Chip Every 1.5 years Called “Moore’s Law”
- Microprocessors have become smaller, denser, and more powerful.
-- Gordon Moore (co-founder of Intel) predicted in 1965 that the transistor density of semiconductor chips would double roughly every 18 months. --
Multi-tasks
- In computing, multitasking is a method where multiple tasks, also known as processes, are performed during the same period of time.
- The tasks share common processing resources, such as a CPU and main memory.
- In the case of a computer with a single CPU, only one task runs at any point in time.
- Multitasking solves the problem by scheduling which task may run at any given time, and when another waiting task gets a turn.
- When task switches occur frequently enough the illusion of parallelism is achieved.

Multi-core
Now all computer has multi-core
A multi-core processor is a single computing component with two or more independent actual central processing units (called "cores"), which are the units that read and execute program instructions. The multiple cores can run multiple instructions at the same time, increasing overall speed for programs amenable to parallel computing.
Co-Processors
A coprocessor is a computer processor used to supplement the functions of the primary processor (the CPU). Operations performed by the coprocessor may be floating point arithmetic, graphics, signal processing, string processing, encryption or I/O Interfacing with peripheral devices. By offloading processor-intensive tasks from the main processor, coprocessors can accelerate system performance.
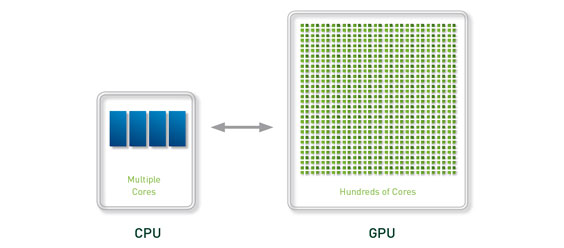
GPU
A graphics processing unit (GPU), also occasionally called visual processing unit (VPU), is a specialized electronic circuit designed to rapidly manipulate and alter memory to accelerate the creation of images in a frame buffer intended for output to a display. GPUs are used in embedded systems, mobile phones, personal computers, workstations, and game consoles. Modern GPUs are very efficient at manipulating computer graphics, and their highly parallel structure makes them more effective than general-purpose CPUs for algorithms where processing of large blocks of data is done in parallel. In a personal computer, a GPU can be present on a video card, or it can be on the motherboard.
GPU computing
GPU-accelerated computing is the use of a graphics processing unit (GPU) together with a CPU to accelerate scientific, engineering, and enterprise applications.
Intel Xeon Phi
Intel Many Integrated Core Architecture or Intel MIC (pronounced Mick or Mike) is a coprocessor computer architecture developed by Intel, the Teraflops Research Chip multicore chip research project, and the Intel Single-chip Cloud Computer multicore microprocessor.
Speedup Factor

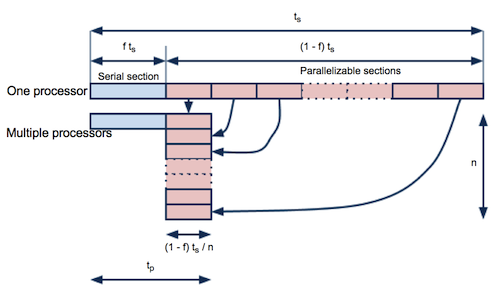
- Suppose you have a code that takes ts~ seconds to run on one processor.
- You find there are parallelizable sections in the code. But for the other sections, it still needs to run on a single processor. (For OpenMP)
- For MPI codes, the processes run in parallel from the beginning, but there must be some parts where all processes do same things.
- Those parts are considered as serial sections.
- The time ratio of the serial section to the total is f , so time for the serial section is ft_{s} and the parallelizable section is \left(1-f\right)t_{s} .
- If you use n processors, the time for the parallelizable section can be reduced to \left(1-f\right)t_{s}/n .
- Here the Speedup factor is defined as
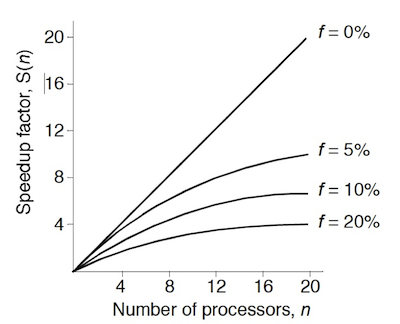
S\left(n\right)=\frac{\textrm{computing time on a single processor}}{\textrm{computing time on multiple processors}}=\frac{t_{s}}{ft_{s}+\left(1-f\right)t_{s}/n}=\frac{n}{1+\left(n-1\right)f}
This is the Amdahl's Law.

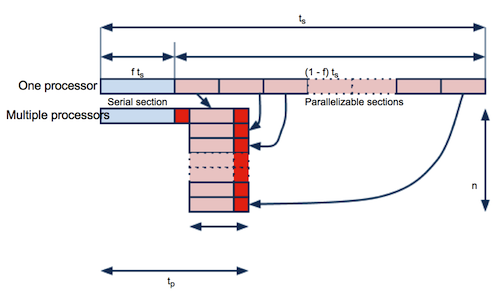
Overhead time
- Since some extra procedures are required for parallelization, there are overheads of each parallel process.
- For MPI codes, the communication between processes is a major overhead.
- We can reduce this negative impact by overlapping communication with computations.
- For OpenMP, there are overhead time at the fork and join threads.

Attachments (7)
- Moores_law_(1970-2011).png (99.3 KB ) - added by 11 years ago.
- Speedup_fac1.png (38.8 KB ) - added by 11 years ago.
- Speedup_fac2.png (58.5 KB ) - added by 11 years ago.
- Speedup_fac3.png (36.8 KB ) - added by 11 years ago.
- CPUpowerDensity.png (796.0 KB ) - added by 11 years ago.
- 6-18-201intelxeonphipciecard.jpg (45.9 KB ) - added by 11 years ago.
- gpu-computing-feature.jpg (25.2 KB ) - added by 11 years ago.
.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip